Are you ready for an adventure?
This website emerges out of teaching data science to students of various backgrounds and my practice in the industry as an engineer and leader.
Mihai Bizovi | Head of Data Science @AdoreMe. As the author of the course (a.k.a book) – all views and mistakes are entirely my own and do not represent any organization.
I aspire to contribute to the understanding of this complex landscape and teach people how to navigate it, how to develop valuable skills, and become more effective at problem-solving. To achieve this, we need to master “the fundamentals.”
I believe that improving decision-making is the reason why we practice AI, but courses often don’t emphasize that. We’re also getting increasingly specialized – which makes us miss the interdisciplinary, big picture.
Decision-Making for the Brave and True
This is an introductory graduate-level, free and open-source course which bridges the gap between theory and practice, cultivating the skills and understanding necessary to bring value to organisations by improving decision-making. It is an attempt to find a golden mean of both worlds:

- Illuminating theoretical ideas (contemplating in the library)
- Practicing battle-tested technologies (engineering in the trenches).
This is the best advice I ever got as a novice data scientist. It is easy to lose track of this simple and elegant idea with the recent advances in statistics and machine learning.
This is the course I wish I had when starting my journey in data science, which would prepare me for the realities of the industry, often very different from the academic world. In my teaching, I achieve this by putting business decisions, understanding the domain, and working software at the forefront of each (statistical) tool we learn.
Anyone lost, confused, stuck or overwhelmed by Data Science and Machine Learning complexities, who wants to see the big picture, a path forward, and the possibilities.
If you stumbled upon this website, you’re probably a student in Business Analytics, or know me personally – well, because I shamelessly promoted it.
Maybe, you’re an engineer getting curious about ML or an analyst with a knack for the business, looking to improve your workflow and expand the quantitative toolbox. Maybe you’re a product manager or an entrepreneur who wants to infuse AI into your startup.
In my opinion, junior data scientists and ML practitioners a few years into their journey will benefit the most from the re-contextualization of fundamentals that I’m doing here, which could enable them to take another leap in career.
The course is challenging due to its breadth (across disciplines) and depth (starting from fundamentals). In service of understanding, it becomes conceptual at times, but I hope you bear with me until you see the benefits of those abstractions. Keep in mind that:
- It is NOT a theoretical course, nor a replacement for probability & mathematical statistics and other prerequisites. There are two possibilities:
- You already had those courses and will look at them with a fresh perspective
- Otherwise, treat it as learning roadmap of the most relevant ideas.
- At the same time, this is NOT a bootcamp, nor a replacement for learning programming in Python/R for data science
- Therefore, it is not enough by itself to land you a job
- For that, there are many wonderful resources for practice and study
Think of it as a skeleton, a conceptual frame1 which ties together everything you have learned so far and can be built upon as you progress in your career and studies. You will probably go back to the same idea years after, with greater wisdom and skill – to unlock its real power.
1 This course stands on the shoulders of giants, and I can only aspire to get to the level of clarity and rigor provided by Hastie/Tibshirani or Andrew Ng when it comes to ML, and Richard McElreath or Andrew Gelman on Bayesian Statistics / Causal Inference.
Given the over-abundance of learning resources, it is too much to sift through a hundred pages of Coursera in the data science section, books, and tutorials to find optimal ones. Inevitably, there is so much bullshit and repetition.
The roadmap provided here should help you navigate it and find the shortest path towards developing your skills and better decisions in your firm. Pick a module you’re passionate about, for example, Bayesian Statistics and look in the resources page for a guide where to start reading and practicing.
Why should you care?
You might’ve heard that data scientist is the sexiest job of 21st century, that AI is going to take over repetitive jobs, Deep Reinforcement Learning models are beating people at Go, Dota, Chess, solving almost-impossible protein-folding problems. The world is awash in the newest ChatGPT and Midjourney frenzy, with new developments every month and week.

You don’t, at least if you want to have a balanced life. That’s why I choose to focus on fundamentals which stood the test of time, which are anyways a prerequisite before you dive into understanding the technicalities of those cutting-edge models and systems.
You will be surprised how far can you go with simple, even linear models. In the end, it is not a competition, nor am I against deep learning: we learn to solve a very different class of problems that businesses encounter.
But what does it actually mean, if we step outside the hype and buzzwords, use a plain language, and apply these ideas in down-to-earth, day-to-day problems and challenges in businesses? It can be a function of decision-making support or the system/product itself, like in the case of Uber, Amazon, Netflix, Spotify, Google and many others.
Even if you are not a data scientist, you will work with them in one form or another (Quant, Data Analyst, Business Analyst, ML Engineer, Data/BI Engineer, Decision-Maker, Domain Expert). Therefore, you have to understand their language, what are they doing, how to ask and make sure they solve the right problem for you.
In university years, you’ve probably been tortured by (or enjoyed) linear algebra, mathematical analysis, probability and statistics, operations research, differential equations, mathematical economics and cybernetics, algorithms and data structures, databases, object-oriented programming, econometrics and so on.
We live in a volatile, uncertain, complex and ambiguous world,2 but we still have to make decisions. Those decisions will bring better outcomes if they are informed by understanding the causal processes, driven by evidence and robust predictions. For a more in-depth explanation of the essence of each subject/domain, read here.
I want you to take away ONE thing, that is “AI” and Data Science in Businesses boils down to: Decision-Making under Uncertainty at Scale
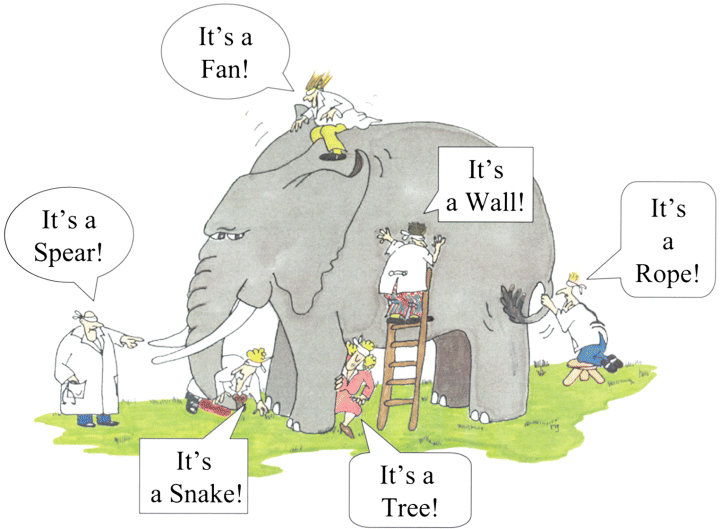
When somebody asks you what have you learned in this book and course, I suggest two metaphors:3 one of simplification and another of seeing relations
3 Due to my philosophical readings, you will see many more such metaphors. There are certain ideas I found tremenously useful in day-to-day life.
![]()
What will you learn?
I am tempted to say “act rationally” to improve business outcomes (top line, bottom line, customer satisfaction, efficiency). However, what you will learn is much more nuanced than that – hence, the short answer below which will take a while to unpack.
\[Question \longrightarrow Modeling \longrightarrow Insight \longrightarrow Action \longrightarrow Outcome \]
Necessary, but insufficient fundamentals in business economics and statistical modeling:
- in order to ask the right questions
- so that we can build custom statistical models
- which bring insight into consequences of actions and interventions
- so that we’re informed which actions that should be taken
- such that a firm can achieve its tactical and strategic objectives
My attempt in organizing the teaching is to split the course into self-contained modules, which can be mixed and matched for diverse audiences and needs. The book will lag years behind my teaching, but the good news is that you can safely use the carefully curated lists of resources and suggested practices.
Conceptual understanding by itself is not enough. So, I curated a list of resources to practice on interesting case-studies, datasets, which directly apply the models, tools, and methodologies presented. These are written by experts in the field, are usually well thought, easy to follow, reproducible, and highlight important aspects of a problem and model.
Also, keep an eye on the course github repo, in which we’ll do some exciting projects (full stack data apps) and investigate common problems/challenges with a fresh perspective.
Prerequisites
I think this course will bring most value to masters’ students, professionals, and students in their last year of BSc – precisely because of presumed exposure or competence in the following subjects:

- For Linear Algebra and Calculus – only exposure is needed, but competence and mathematical maturity will help a lot. If you need a refresher, a crash course will do (for example, Grant Sanderson’s “Essence of LinAlg”)
- For Probability Theory – competence is needed, even though we start from the very beginning (review of combinatorics). I suggest you read along and practice with a more comprehensive resource, like Joe Blitzstein’s “Probability 110”
- For Mathematical Statistics the story is the same as for Probability. You will need at least to be familiar with hypothesis testing and regression. This course can catalyze the process. My favorite resource so far is Huber’s “Modern Statistics for Modern Biology”.
- Python or R programming for Data Science is mandatory, including data wrangling, visualization, scientific computing, databases. I recommend two free books:
- “R for Data Science” by Hadley Wickham
- “Python for Data Analysis” by Wes McKinney.
- Of course, the more experience you have in one or both, the better
- This is completely optional, but if you have to deal with financial statements at your job or have an interest in finance, I strongly suggest you check out A. Damodaran’s crash course.
Module 1: Business School for Data Scientists
I always start with an exploration of decisions that businesses face across many industries and use-cases. Then, I clarify what does AI4 mean and where does it add value, what is the difference between Analytics, Statistics, and ML.
4 Remember “Decision-Making Under Uncertainty at Scale”
In this module we focus on understanding the business domain, the problem space, learn how to ask good statistical questions in context of firm’s strategy. An essential aid in this pursuit are different processes and methodologies that get us from question to insight, action and outcomes. However, at this point we lack the actual modeling know-how, which is a good segway to the next module.
“What is methodology good for? Sounds like I could use that time to learn ML”
These methodolgical fundamentals are not “just theory”, it is what will make or break projects in practice. There are so many pitfalls in ML and statistics that we cannot afford to do it ad-hoc. In contrast, taking a systematic approach will dramatically increase our chances of succeess.
If you worry that the business school is too conceptual – don’t despair, as we’ll have three very techical lectures, involving math and programming.
- I use the newsvendor problem as a starting point in modeling for demand planning
- The pricing optimization as a starting point towards revenue management
- The Learning Problem highlights and formalizes what is at the core of Machine Learning – in what conditions can we learn from data, generalize
Module 2: Probability and Statistics
If we view statistics as changing our minds and actions in the face of evidence – the good ol’ t-test will shine in a new light. It will become clear why those models and procedures were invented in the first place.
Some lectures are heavier in mathematics, especially when talking about estimators and their properties. We’ll use stories and simulations as much as possible to boost our intuition.
We will go far with simple, elegant models; appreciate the importance of asking the right questions, persuasive communication, and storytelling with data. That’s why it’s essential to take every tool and apply it in the context of an appropriate use-case/application – meaning, we’ll code a lot. You will not be puzzled anymore where those wild distributions (Poisson, Hypergeometric, Weibull, …) come from (what are their stories) and where are they used.
The module culminates in practical aspects of A/B testing, sample size justification and power analysis, experiment design, and a conversation about the causes and remedies to the replication crisis. After all this effort put into the study of fundamentals, you can go with ease and confidence into Bayesian Statistics, Machine Learning, Causal Inference.
In statistics’ classes, the problem is usually completely framed and students focus on computation / interpretation. Experiment design in practice is tricky and more complicated than it looks – especially when it comes to pricing and recommender systems. That’s not your stats 101!
My preferred sequence is to go in parallel with the “business school” and stats, since there is a great synergy. The prior focuses on the process (over content) of analytics, ML, statistics. The prior focuses on the problem and not so much on solutions.
Module 3: Applied Bayesian Statistics
Once we have a confident grasp of the fundamentals, we continue on the path of Applied Bayesian Statistics. It is an extremely flexible and “composable” approach to building explainable models of increasing complexity and realism.

Instead of applying an out-of-the-box model, we will build custom ones for each individual application in an iterative way. Choosing appropriate probability distributions and modeling assumptions will be critical in this process, along with model critique and validation.
Many experts in the field argue that this should be the default way we do regression analysis and that we need a very strong justification to show that a linear regression is the appropriate model.
To put it bluntly, this modeling approach will enable us to improve on most challenges in decision-making and inference that businesses face.
One notable difference between the Bayesian approach and the traditional way advanced econometrics is taught, is that we will focus on computation instead of proofs and heavy-duty mathematical statistics. We declare the model and the sampler does the job for us! If it explodes, we probably modeled it wrong.
Notes about Causal Inference and ML
Did you get comfortable with building custom statistical models for inference and prediction? What about decisions with high stakes, where we sometimes want to do randomized experiments?
Often, A/B tests and randomised experiments are unfeasible or unethical. Also realize that we cannot reach a causal conclusion from observational data alone – we can talk just about associations. We need a theory, which is our understanding of how the “world” works – translated into a statistical model, plus data, which will give us new insight into the causal processes (the evidence).
This motivates a deep-dive into the field of Causal Inference – a link between the theoretical models and observational data, where we sometimes can take advantage of certain “natural experiments”. Causal inference requires deep thinking and understanding, which is truly challenging – an art and science, in contrast with the “auto-magic”, unreasonably effective pattern recognition of ML.
Even if you’re interested only in machine learning, most practitioners will emphasize the importance of mastering regression (often starting with generalized linear models) and doing A/B tests resulting in evidence that our new model brings an improvement (or not).
This is how we jump through various buckets, highlighting the golden thread linking them all: decisions and uncertainty. Moreover, the tools we learned in Bayesian Statistics are directly applicable in ML – the lines between these two fields are indeed very blurry.
Often, we care not just about a single decision or developing better policies, but we have to make tons of little decisions at scale. This is when we switch to a predictive, Machine Learning perspective and walk through our workhorse models, which should serve us decades ahead in a wide range of applications: both predictive and exploratory.
The icing on the cake is miscellaneous topics dear to me and usually not covered in such a course: Demand Forecasting, Recommender Systems, and Natural Language Processing. All extremely useful in business contexts, but significant tweaks are needed to the models discussed before.
Full-Stack Data Apps
During the labs we’ll build from the ground up a tech stack for reproducible data analysis, model and data pipelines, culminating in a full-stack data app (with user interface, backend, database), which solves a real-world problem.

That is your final project for the course and something you can brag about in your portfolio and github profile. It sounds complicated, but we have the tools to make it easy for us. Don’t worry about getting everything right, but focus on a problem and single area from the course you’re passionate about: be it data visualization, ML, statistics or sheer engineering curiosity.
- For engineers: if you like programming
- Interactive, data-driven application to support decisions
- A CLI app to train a model
- For analysts: if you like data analysis
- Answer an interesting question, with some inference
- Showcase your findings in a quarto blog
- For data scientists and statisticians:
- Solve a business problem with models
I haven’t done any writing on ML, Causal Inference, or building full-stack data apps. The idea is to bring new insights and ways of learning, since there are already many excellent resources on the web.
Here are the future modules on my backlog. I will start working on them only after I feel like the book is rock solid in teaching the fundamentals.
- Module 4: Causal Inference and Directed Acyclic Graphs
- Module 5: Probabilistic Machine Learning
- Module 6: Deep Learning and Special Topics
- Module 7: Software Engineering and Full-Stack Data Apps