Business context
Applications, Strategy, Performance
In the introduction, I loosely explained how decision science can contribute to improving firm’s performance and outlined some common applications. We saw how important is to understand the domain (like marketing, supply chain) and problem space by taking the point of view of our clients and decision-makers.
The environment many businesses operate in, is volatile, uncertain, complex, and ambiguous. The best way to learn to navigate it, is experience on the job and a solid background in business fundamentals.1 For example, if you’re a data scientist doing demand planning for a fashion e-commerce, it’s a good idea not only to review the forecasting literature, but also to understand the demand and supply particularities of the industry. Find a colleague who is a domain expert and learn as much as possible from them.
1 People do business degrees, go into consulting, business analytics or MBAs for that.
I mean, there are no universal recipes in a business – it takes knowledge, experience, a well-exercised toolbox of models and frameworks to make good decisions. In this chapter, we will first discuss one way of thinking about diagnosis, what is strategy, and the value chain of the firm. Then, I will present in more detail the applications from the introduction and what quantitative tools might be helpful in tackling them.
Warm-up exercises
During a lecture, I usually ask students to give some examples of businesses, sevices, technologies, problems, and domains which have ML algorithms and statistical models behind the scenes.2 Did you take an Uber lately, watched a movie on Netflix, bought a t-shirt, got a credit card, had to update your insurance, went for groceries?
2 Of course, there is that one person very passionate about sports, finance, or blockchain.
Put yourself in the shoes of those businesses and think carefully about what strategic and operational decisions they have to make.
- What is the client need or problem and what value it adds?
- What was the firm’s objective?
- What constraints did they hit? Why was it a difficult problem?
- What made it an appropriate use-case for ML, Statistics, and AI?
- What would be a baseline, simple, or naive solution?
If you have a hard time picking an example, choose a direct-to-consumer e-commerce, like Zara, H&M, or a marketplace like Zalando.
In the case of Uber, Bolt (ride sharing platforms), we’re very much interested in same questions as before. However, we need to get a grasp on the idea of market-making. If you were to reverse-engineer their pricing algorithms, how would you go about doing it?
It’s ok it you can’t answer some of the questions yet, but one sign of growth as a decision scientist is when you have a pretty good idea of what systems and methods are powering Uber, for example. By the way, those firms often brag about it in their tech blogs, which gives us not a complete solution, but a decent working hypothesis.3
3 In this course you no longer are the consumer, but you have to think like an employee of those firms
There is one philosophical question you have to answer for yourself: “What is the purpose (raison d’etre) of a business?” People will give different weights4 to the following options, depending on their background, context the question is asked in, beliefs, and aspirations.
- Maximize profits and gross margin?
- Gain market share, grow, and maximize future discounted cash flow?
- Maximize shareholder value?
- Bring added value to customers by solving a problem?
- Contribute to economy and society (tax, employment)?
- Create new markets to allocate resources efficiently?
Are you considering to start a business in the next 5 years? Now, imagine you’re in charge of public policy or participating in a think-tank / NGO for youths. Formulate a research question that a further study would try to answer regarding students’ entrepreneurial intentions and perceptions.
4 We can use a 1 to 5 scale from strongly agree to strongly disagree, also called Likert scale
The first thought experiment shows you how prevalent are applications of ML and statistical modeling. The second one highlights how difficult it is to take a vague research question, hypothesis, or idea and design a study which has a good chance of answering it. It will take a lot of practice to formulate those questions well.
There is a good reason why management consultants practice Fermi Estimation to do sanity and order-of-magnitude checks. Such problems are asked in many interviews: “how many people are online on Facebook right row?” or “what is the potential market size for socks in the US?” All of those are multiplicative processes and formulas.5
Take a look at the case study on food stamp fraud by Carl Bergstrom and Jevin West in Calling Bullshit. Practice on other classical Fermi estimtion examples from this video of Phil Wilson.
Then, try to come up with a guess-estimate of how much revenue does your university canteen is generating per year. Assess the estimation and refine your assumptions.
5 Therefore, we can use the geometric mean for the quantities we only can put a range on, but don’t know their exact value.
Fermi estimation teaches us that we can be systematic, even when making back-of-the napkin, rough guesses. We have to make our assumptions clear about the known and unknown quantities, their plausible ranges and refine those when the result doesn’t make much sense. A fantastic book on climate change by David McKay, “Without the hot air”, heavily leverages Fermi estimation to assess what each country can feasibly achieve with renewable energy.
Diagnosis and Strategy
You probably encountered before the SWOT analysis and SMART criteria for setting objectives.6 Those are good tools to start with, but can be easily misused and result in fluff. In order to avoid those vague answers and not to fool ourselfs, we need to start thinking like scientists, which we’ll begin to do here and elaborate in the next chapter.
6 Strengths, weaknesses, opportunities, and threats. Specific, measurable, achievable, realistic, time-bound. Yes, management consultants absolutely love acronyms
Kim Warren’s paper “The Dynamics of Strategy”7 was the best investment of an hour in my professional journey. It will teach you to think about accumulation of strategic resources, rates of in-flow and out-flow, feedback loops, drivers of those rates, and decisions influencing the whole system.
I will summarize below the most important conceptual and practical arguments from the paper, but there is no replacement to actually reading it.
7 Which summarizes well his book “Strategic Management Dynamics” (Wiley, 2008)
8 The paper thinks of causes in a systems’ dynamics sense, not in a statistical sense of associations and influences
The first insight is that we need to look at history, dynamics, trajectories of how and why we ended up in current situation. We need to understand “how our business works”, the causes of performance, since current resources and capabilities with be determining to a large degree what will happen in the future.8 This understanding needs to be quantified, measured, and backed up by data.
By resources, I mean concrete or intangible “stuff” which can be accumulated in time, as a cash, equipment, products, production lines, a customer base, employees, brand reputation, employee expertise, etc. Formally, they’re stocks and measured at a point in time. On the other hand, we can look at performance in terms of sales, profitability or non-financial measures of customer retention, satisfaction, acquisition, brand recognition, production efficiency, etc.9
9 The best practices for measuring performance will vary depending on the domain and is a topic of study in itself
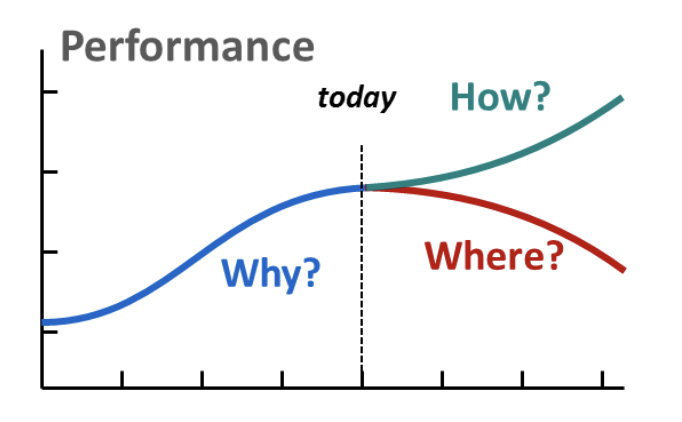
Before we discuss the technicalities and practical relevance of the systems dynamics perspective10 of a firm’s performance, let’s think about the trajectories in the diagram above. This way we easily generalize a SWOT analysis to take into account the history and quantify the claims.
10 Note, that this is the closest we have to “a science” in businesses and strategic management
- If we keep doing everyting as before, what is the most likely trajectory of profits? Under what assumptions? If the trajectory is promising to us, that is our strenghts and capabilities contributing to it. If not, our weaknesses.
- A feared trajectory, e.g if our business is hit by a supply chain shock, crisis, competition starting a price war, or weak customer demand. It’s the threats a firm is vulnerable to
- A desired or aspirational trajectory. Is it reasonable and realistically achievable? If yes, what strategy and tactics should we implement, how sould we act? This is our opportunity.
Stocks, flows, and dynamics
If we want to launch a beer brand which sells in lots of grocery stores, our “resources” on the demand-side are customers, stores (as intermediaries), and marketing people responsible for advertisement and pitching it to stores. If we want to open a new restaurant, we talk about customers, staff, and the menu (our product).
It’s useful to classify supply-side resources into capacities (machine, aircraft seats, stores, production lines), staff (engineers, pilots, sales, factory workers), and product. Resources grow by getting an in-flow \(\psi_{in}(t)\) at a given rate, which could be nonlinear and explained by drivers such as advertisement, availability, training. We should also remember that we can lose customers due to disinterest, churn, competition; we can lose employees due to dissatisfaction. This reduces our stocks by out-flows \(\psi_{out}(t)\).11 The flows are measured in units per time interval, e.g. new acquired customers per month.
11 I know all of this sounds tedious, but it’s the only way to rigorously reason about performance: stocks and flows!
Our first equation tells us that the current level of resources (vector R) is given by the cumulative net flows over the whole history. It might take a long time and investment to accumulate resources needed to achieve the desired performance. This idea gives us a straightforward interpretation for the barriers to entry.
\[\begin{align} \mathbf{R}(t) & = \int_0^t r_i(t) dt + \mathbf{R}(0) \\ & = \int_0^t [ \psi_{in}(t) - \psi_{out}(t) ] dt + \mathbf{R}(0) \end{align}\]
The second equation “simply” tells us that the current level of performance depends on the resources, our decisions, and exogenous factors. We’ll have to do the hard work of translating our business understanding into the mathematical relation, i.e. define \(f\).
\[ \pi(t) = f(\mathbf{R}(t), D(t), E(t)) \]
At last, the rate is a function of available resources, decisions, and exogenous factors. Notice how (1) and (3) allow for reinforcing and balancing feedback loops. Kim Warren’s paper goes at great lengths to define those and give practical, ubiquitous examples. We’ll come back to the topic when doing simulations.
\[ r_i(t) = g(\mathbf{R}(t), D(t), E(t)) \]
As an example of reinforcing feedback, think of the word-of-mouth growth of a shop: some of our happy customers recommend it to their friends, which in turn could become our customers. These loops influence the in-flows and are not always this happy – think of the debt deflation during the Great Depression of 1929. Another common example is of a shrinking business due to cost cutting, which leads to the inability to meet and sustain demand.12
12 In my opinion, many businessed today are run in a very short-sighted way, with a short-term, ruthless focus on financial outcomes and maximizing shareholder value. I’m not saying this from a moral point of view, but for their own good and long-term, sustained performance
In contrast, if we have a neighborhood restaurant, the number of remaining potential customers will drop with each new regular. Moreover, if it is so successful as to have large waiting times, we’ll hit a fundamental constraint of capacity, meaning the waiting times will limit the number of customers per week. These are balancing loops, fundamentally concerned with out-flows.
First, by drawing the stock-and-flow diagrams, the relevant feedback loops, defining your assumptions, functional relationships, and parameters to tweak. We’ll have to collect data to estimate the unknown quantities and to have a ground-truth of performance. At last, we simulate and explore different scenarios – which should give us insight into how “the system” works and what should we do.
I know this is not easy to do well in practice and no wonder that systems’ dynamics is almost not used at all in businesses. Still, they are missing out on a powerful tool! But know that at the very least, this way of thinking will contribute to a much better diagnosis and strategy than if you weren’t aware of it. You could capture the nonlinearities and the dynamic complexity of the business, something which a rule-of-thumb, 3-scenario of profitability excel sheet can’t ever dream to do.
Physicists, biologists, and chemists develop mathematical models which result from their hypotheses and theory. They design experiments and statistical models in oder to see if those hypotheses are plausible.
The models which describe real-world causal mechanisms are also called process models, as they take a vague hypothesis and make it concrete and testable. In the most happy case, the statistical models and their parameters are identifiable (i.e. uniquely correspond to that theoretical model).
In social science, we can’t even hope for such results. But if you take this analogy far enough, the equations resulting from stock-and-flow diagrams are our causal, process models. They will fail to capture the full complexity, but they should be useful in decision-making and strategic planning!
Strategic alignment
So, you found out this new (but old) way of thinking and modeling a firm’s performance in a competitive market and VUCA environment – but what is strategy, after all? Following Richard Rumelt’s argument in “The perils of bad strategy”, it is easier to define what it’s not.13
13 I hope when you see fluff strategy, you recognize it and call it out as such!
In short, it is not just aspiration towards a goal or having a vision or setting a target, and hell no, it’s not a wishlist. By analogy, remember the SMART criteria when you’re setting goals. As true consultants, we can summarize the steps involved in developing a strategy in a matrix.
| Step | Outcome | Characteristics |
|---|---|---|
| Honest diagnosis | Identify obstacles | Few critical, relevant challenges |
| Guiding policy | General approach to overcome challenges | Focused on key aspects |
| Coherent actions | Support policy with action plan | Coordinated and focused |
Since strategy informs so much of decision-making, know your firm’s strategy – ask around, understand it, contribute to it. Call out bad strategy, especially when it tries to deal with everything all at once.
Following the strategic resources argument, we can view a team which can operationalize machine learning systems, statistical models, and optimize processes at a large scale as an important capability and competence to develop inside a firm.
As the firm (hopefully) has a strategy, a “data science” team should also have one, in order to know what work to prioritize and where can they bring the most value. So, our next challenge is how can we align business objectives with data science use-cases.14
This is where we have to think about the value chain of the firm, how it adds value from customer acquisition, engagement, to manufacturing and sourcing of materials. For each function of the value chain, we have to define the critical KPIs which assess its performance, derive use-cases which attempt to improve and are aligned to those metrics.
In turn, for each use-case, there are critical factors influencing the use-case and data points which serve as proxies or measures of the drivers. We’ll collect the data from the appropriate (software) systems which generate it and build pipelines to transform it in a clean, usable format on schedule or whenever we need it.
14 I highly recommend the article published on the blog “bayesian quest”, named “Data Science Strategy Safari”. It saved me tons of headache.
Notice how our approach to learning, strategy, and problem-solving is systematic, starting from first principles. At the same time, having a methodology doesn’t mean we’re following a mechanical process, a rigid procedure – as you see, there is plenty of space for creativity.
Take a subscription-based publication like London Review of Books and analyze it using the tools and frameworks you learned.
Think about acquisition, churn, printing, transportation, and market share. How can it grow? What would make it profitable? What are the key decisions to be made?
The value of methodology
An essential aid in this pursuit of improving decision-making at scale, are different processes, workflows, and methodologies for machine learning, experiment design, causal inference, and exploratory data analysis.15 It is important to mention that methodology is not a recipe, but way of structuring our work, a set of guiding principles and constraints over the space of all the things that we could do in analysis. Don’t think of these constraints as limiting your freedom, but as helpful allies in effective problem problem solving.
15 We’ll discuss it in detail in the next chapter
These methodolgical fundamentals are not “just theory”, it is what will make or break projects in practice. There are so many pitfalls in ML and statistics that we cannot afford to do it ad-hoc. In my teaching, I try very hard to bring back the scientific process and methodology into decision science, as understanding and applying a statistical tool or model by itself is not sufficient.
A lot of attention has been paid in the industry to the software engineering aspects of machine learning as one of the causes of failed projects. In the last 5 years, a lot of tools and best practices have emerged which can help us mitigate those risks and operationalize successfuly.
In my opinion, a bigger problem is methodological and organizational: a mismatch between business objectives, actions, constraints, tradeoffs, domain specificities vs modeling. This is why the ability to ask good questions, to formulate a problem, and think scientifically is critical. Therefore, an important goal of my writing is to recognize and avoid adhockery. 16
There is one more problem you have to be aware of, which I call the “Kaggle phenomenon”. Despite Kaggle competitions being an excellent platform for honing ML skills and developing better models, I think it gave too many people the impression that this is what data science is about. Kaggle misses the most important aspects of problem-solving and it is devoid of most of the original business context and decision-making.
16 Adhockery in modeling, in product-management, in data-mining, and software engineering
So, we’re moving from a strategic level of analysis to individual use-cases, where we have to think like a product manager, if we want our solution to be useful. For this, I found the Event Storming workshops from Domain-Driven Design and Google’s People+AI Research (PAIR) workbook really helpful.
I have also written a guide about how to think about GenAI use-cases. “Fundamentals of GenAI governance”: A conceptual framework for AI product managers
Perhaps, you won’t need to worry about the firm’s strategy and will have a really good product manager driving the project, so you can focus on modeling and data analysis. However, this is more of an exception than the rule in most businesses – which means that you have to be aware of some product management and consultancy techniques to get by. These skills become tremendously important when you transition into a management and leadership role, be it in business or tech.
Applications
In the course introduction and the first part of this chapter, you saw that ML and statistical modeling has applications in most industries and domains. I’ll give more examples here, highlighting what tools we’re going to study are helpful in tackling these problems. I’ll remind you that we’re talking about systems and models for decision-making under uncertainty, and sometimes, these decisions are at a large scale (for which you would normally need an army of employees).
In pharma, we need to rigorously design randomized control trials and take into account the dropout, censoring, and other threats to the validity of the study. These studies are very expensive, highly regulated, which limits sample sizes and the kind of interventions allowed. Moreover, it is very difficult to assess rare side-effects and the long-term consequences of drugs and treatments.17
17 This is why a good statistician is essential to pharmaceutical firms and research labs
In market research, the question is what is the potential market size, consumer interests, perceptions, preferences, and patterns of behavior. This helps firms decide whether to enter into a market, what products to develop, and where they stand with respect to competition.
In political science, as in market research, surveys and self-report is the main quantitative research method used – which poses challenges of non-representative samples, non-response, measurement error, and the mismatch between self-report and actual behavior. Statistical approaches like multilevel modeling with post-stratification are essential tools to deal with these challenges.
Moving on to sports science, Liverpool F.C. won a title and a key part of their success was leveraging AI and ML to discover new tactis on the field with the highest payoffs. NBA teams invested a lot in the data infrastructure and decision-making capabilities: LA Lakers found the best player for a particular position they were lacking. Houston Rockets won the regular season by going all in on the 3-point shot.18 Golden State Warriors simply revolutionised basketball with data, before everyone else was doing it – giving them a competitive edge. 19
18 Moreyball: The Houston Rockets and Analytics – an article in Harvard’s MBA Digital Innovation
19 Check out the following video by The Economist on how data transformed the NBA. For more details on the statistical methodology, I enjoyed an youtube channel called Thinking Basketball and their playlist about the statistical methodology.
A classical application in automotive industry is predictive maintenance, where we can use time-to-event modeling to replace risky parts before they go out of function. In manufacturing, we can leverage what we learned about hypothesis testing and apply it for quality control.
Pricing and revenue management
In the case of Uber and ride sharing platforms, we’re not only concerned with matching passengers and drivers, allocating routes, and setting the right prices at scale – we’re talking about managing a whole competitive market (supply-side and demand-side). 20
20 When it doesn’t work out – I’m pretty upset at their data scientists and domain experts. Here is where ethical issues creep up: jacking up prices, monopolies, drivers struggling to make a living wage.
Thus, a dynamic pricing solution should capture the causal patterns and uncertainty in demand, which is driven by weather, seasonality, competition, and exogenous events. Because they are a platform and market-maker, machine learning models for demand forecasting won’t be enough, especially when quantifying the effects of pricing decisions – so they must take into account the economic theory.
It is possible that they need to do lots of experiments in order to collect the necessary data to train and estimate those models. At last, even when having reliable predictions of the consequences of pricing decisions, they’re left up with a large allocation and optimization problem, as there are only so many drivers.
When optimizing prices under limited capacity of airplane seats, concert tickets, hotel rooms – we need econometric and ML models for demand forecasting and sophisticated optimization algorithms, including dynamic programming. This new field of revenue management has a rich research literature and sophisticated proprietary solutions.
Demand Planning
Demand forecasting and inventory optimization is needed any time there is uncertainty in demand and we have to decide how much to produce, purchase, or capacities to allocate.21 Things get much more complicated as the product catalog grows, as products are distributed in multiple places (like stores) and channels.
21 In retail, fashion, apparel, e-commerce, hospitality and recreation, pharma and healthcare, automotive, etc
Moreover, errors in forecasting propagate and amplify through the supply chain, making the sourcing and manufacturing decisions harder if there is no end-to-end sharing of information.
In the paper “Newsvendors Tackle the Newsvendor Problem”, Koschat, Berk et. al. show how an analysis and optimization of printing decisions led to TIME INC. to revise its policies and generate additional \(\$3.5m\) in profit. I will present this problem in the context of simulation and statistical modeling lectures, and we’ll apply it to Yaz restaurant data.
Despite the simplicity of formulating the newsvendor problem, one can go into a lot of depth both on forecasting and optimization, as shown in a meta-analysis of data-driven approaches to it, by S. Buttler, A. Philippi. Generally, machine learning models like LightGBM with thoughtful feature engineering (including promotions, availability, and other demand drivers) work very well for demand forecasting, but not always.22 Sometimes, a top-down forecast or traditional time-series methods make more sense.
22 In the meantime, Conformal Prediction has emerged as an important technique to quantify the uncertainty in forecasts of ML models, but there are also other ways based on simulation
If you have a demand planning use-case at work, I highly recommend Nicolas Vandeput’s books, articles, and lectures on best practices in demand planning and I. Svetunkov’s Lancaster University CMAF seminars.
Churn and Lifetime Value
Besides acquisition, customer retention and repurchase is what makes or breaks businesses, especially in the past few years, with so many subscription and SAAS products. Therefore, we need a set of methods to predict customer churn and lifetime value in contractual and non-contractual settings. At a first glance, these might look like a simple classification problem which is easily solved with a ML model, but things are more complicated.
First, we might need some tools from survival analysis, as we care not only about the probability of churn in the next month, but the expected time until churn.23 Second, we really want to know who can be convinced to remain or purchase again (via an intervention like promotions or loyalty program).
23 Survival analysis answers the question of what is the probability a customer remains for a given time horizon, given they are active until now
There is a body of work spanning two decades by Bruce Hardie and Peter Fader, who developed statistical models that estimate the remaining LTV (Lifetime Value) of customers, which depends on their survival, activity, and repurchase patterns. These “Buy till you die” models work very well at the level of a customer base, which is useful in financial planning and forecasting.